Auto-claude-code-research-in-sleep (ARIS ⚔️🌙)
💡 Use ARIS as a skill-based workflow in Claude Code / Codex CLI / Cursor / Trae / Antigravity / GitHub Copilot CLI / OpenClaw, or get the full experience with the standalone CLI — enjoy any way you like!
🌱 ARIS is a methodology, not a platform. What matters is the research workflow — take it wherever you go.
🔥 ARIS natively fits — and already supports — any agent's ultracode-style deep mode: its breadth pass adapts to whatever a runtime exposes — Claude Code's ultracode / dynamic workflows on Opus 4.8 (xhigh, or max effort if budget allows), Codex spawn_agent / equivalents, or another model entirely — degrading cleanly parallel fan-out → agent spawn → plain sequential.
ultracode supplies firepower to the breadth half ARIS always had, giving three clean roles: depth → breadth, cross-model review → accuracy, research wiki → memory.
However a loop is driven — ultracode breadth or goal-mode persistence — every loop reports to the same cross-model jury + research wiki: it can drive, never acquit.
🤖 AI agents: Read AGENT_GUIDE.md instead — structured for LLM consumption, not human browsing.
🚀 Beyond 科研 → 任何 "研究":ARIS-Anything 把 ARIS 的五步 loop(plan / draft / 对抗审 / 迭代 / 持久化)推广到非学术的结构化研究——投资尽调 / 法律研究 / 市场研究 / 自驱学习 / 调查新闻 / 工程复盘等。Incoming siblings:🎬 ARIS-Movie(长视频生成 + movie wiki 对抗审)· 📐 ARIS-PRD(产品需求文档)· 🎨 ARIS-Design(设计 brief 对抗评审)· 🏋️ ARIS-Gym(skill 跑分 + OpenAI-Gym-for-research-agents 的 meta 评测层)。
🎯 准备 2026 AI 秋招? → 🌐 ARIS-in-AI-Offer 网页版 · GitHub repo · 中文 README · 23 篇双语 ML / LLM / 多模态 / 生成式 / Agent 面试 cheat sheet 合集——每篇公式推导 + 从零 PyTorch 代码 + 25 高频面试题(L1 必会 / L2 进阶 / L3 顶级 lab),全部由 ARIS 的 /render-html workflow 自动生成。🚀 Just shipped (2026-05):🌐 ARIS-Homepage v1(/homepage-generator skill)—— fact-check 你的简历再生成单文件个人主页:CV → DBLP/arXiv 自动 audit venue/年份/作者,硬失败拦截 venue/年份不一致与疑似编造奖项 → 单文件 HTML。Live demo → · 📝 Plus (2026-05-28):第一篇 long-form blog —— Continuous DLM 2026 H1 综述(6 篇论文:ELF / ByteDance Cola-DLM / Flow-Matching 全景对比),跨模型协作写成(Claude Opus 4.7 × Codex GPT-5.5 xhigh × Gemini auto-gemini-3)—— 展示 /render-html 能产出的 long-form 研究分析深度。 · 希望大家秋招的时候轻松一点 🌱
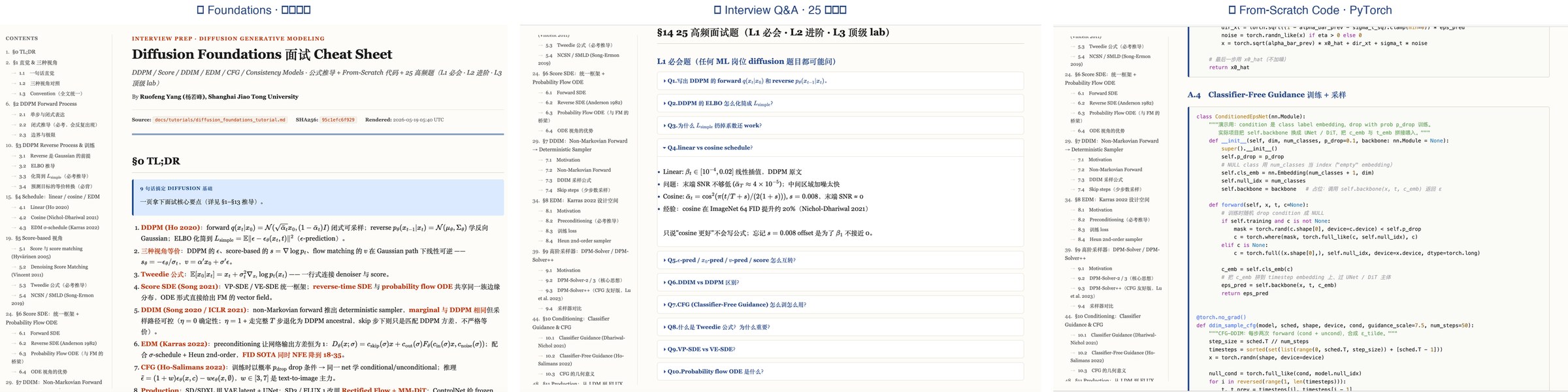
📖 Preview from the Diffusion Foundations cheat sheet — every tutorial in ARIS-in-AI-Offer follows the same three-pillar structure (foundations / interview Q&A / runnable code).
🌐 Same workflow, different deliverable — ARIS-Homepage v1 live demo (CV → fact-checked single-file academic homepage via
/homepage-generator).
🛰 社区好物 · Claude Fleet(by @tianyilt)—— 一个本地只读数据看板,同时盯住你开的一堆 Claude Code / Codex 窗口:triage(谁在干活 / 等你点权限 / 跑完了)· 一键 Focus 跳到对应终端 · ~50ms 全文搜所有 transcript · skill / memory 用量分析。像 ARIS 这种动辄并行一片 agent 的工作流特别合适。好用的话点个 ⭐
Run it in 30 seconds
git clone https://github.com/tianyilt/claude-fleet
cd claude-fleet && bash run.sh
# open http://127.0.0.1:7878 in your browser
🔥 ARIS-Code CLI — 独立安装版 · English | ⬇️ Download
|
📰 ARIS-Code v0.4.5 → v0.4.15 (2026-05) — an eleven-release polish run: new providers (DeepSeek V4 Pro / Xiaomi MiMo / Qwen 3.6 / Doubao / Custom OpenAI-compatible / DashScope), first-class reasoning + tool-use, stream + MCP reliability (closes #228 / #151 / #172 / #249), security hardening (system-prompt secret redaction; opt-in |
Per-release details (v0.4.5 → v0.4.15)
v0.4.15 (2026-05-29) — OpenAI-compatible streaming robustness hotfix. Closes #249: MiniMax (and other OpenAI-compatible providers / proxies) were effectively unusable because the clean-EOF completion check treated the
data: [DONE]SSE sentinel as the only authoritative signal. A non-emptychoices[].finish_reasonis the Chat Completions spec's terminal-chunk marker;[DONE]is a transport convention some compatible providers never emit (MiniMax sendsfinish_reason: "stop"then closes without[DONE]). The clean-EOF decision is now a pure, unit-testedstream_eof_action(...)that completes on EITHER[DONE]OR a non-emptyfinish_reason; reads are NOT stopped early at finish_reason (a trailinginclude_usageusage-only chunk is still consumed), genuine truncation still hard-errors, and a pre-output proxy abort still restarts. Coupled fixes: OE7 reads finish_reason before thedeltaguard (delta-less terminal choice); OE2 flushes pending tool calls on any non-empty finish_reason; OE4 surfaces a mid-stream error envelope as a hard error instead of silently dropping it; OE3 toleratesdata:{...}without the space after the colon. +5 unit tests (77→82) extract the previously-untested SSE completion logic into pure helpers. Anthropic SSE path untouched. Codex MCP (gpt-5.5 xhigh) 3 rounds (GO-WITH-NITS → GO-WITH-NITS → GO).v0.4.14 (2026-05-25) — Security-hygiene release closing the top items from the v0.4.13 codex audit (gpt-5.5 xhigh, 6/10 NEEDS-REWORK verdict). 🔴 S9 (P0) system-prompt config redaction — before v0.4.14,
render_config_section()dumped the mergedsettings.jsonverbatim into the system prompt sent to the LLM provider, leakingenv,mcpServers.<name>.headers.AuthorizationBearer tokens, hook command env, signed-URL query params, andapiKeyfields. New renderer whitelists top-level fields (model/permissionMode/theme/outputStyle/permissions/sandboxwith recursive redaction inside), redacts sensitive keys (apikey/token/secret/password/authorization/headers/env/_KEY/_SECRET/_TOKEN), replaces MCPcommandwith<configured>placeholder, reduces MCPurlto strict<scheme://host[:port]>origin (scheme allow-listhttp/https/ws/wss, ASCII host, digit-only port, IPv6 brackets), and drops hook command strings entirely. Regression test exercises 9 distinct leak surfaces; URL parser has its own targeted test for 7 smuggling attempts including port-position secret injection (codex round-3 catch). 🟡 P9 (P1): DeepSeekaris --helpnow points ataris setupoption 7 instead of an env-var path the resolver never honored. 🟡 M1/M2 (P1) doc:aris doctor+ README/README_CN gain experimental warning whenevermcpServers.len() > 0(full MCP tool dispatch lands v0.4.16). 🟢 C11 (P2) stream idle timeout — both AnthropicMessageStreamand the OpenAI SSE loop wrapresponse.chunk().awaitintokio::time::timeout(envARIS_STREAM_IDLE_TIMEOUT_SECS, default 120, clamp[10, 1800], 0/negative disables); closes the "aris hangs forever with no output" symptom when an upstream HTTPS proxy holds a connection without keepalives. Bundle: 77 skills (+1/wiki-enrichvia late same-day sync to main7e3ab67which also picks up upstreamcheck_ready.shawk + grep-c null-match fix), 54 helpers. Codex MCP 6 rounds (NO-GO + 4 → GO-WITH-NITS + 3 → NO-GO + port smuggling → GO → release metadata GO → sync GO).v0.4.13 (2026-05-25) — Residue-cleanup release closing every codex audit P1 carried since v0.4.10–v0.4.12, plus the long-tail regression tests. 🟡 v0.4.10 P1.D per-server MCP timeout —
mcpServers.<name>.requestTimeoutSecsoverride >MCP_REQUEST_TIMEOUT_SECSenv > 300s default (clamped 1..=1800), so one Codex MCP agent can run 5 min while filesystem MCP errors in 5 s. 🟡 v0.4.10 known limitation closed —McpStdioProcess::request()skips JSON-RPC notifications (id absent/null) and keeps reading until the correlated response. 🟢 meta_opt hook deploy viaaris init—tools/meta_opt/{log_event,check_ready}.shbundle into the binary;aris initwrites ARIS-namespacedaris-meta-opt-log-event.sh/aris-meta-opt-check-ready.shto~/.claude/hooks/(codex round-1 #1: never clobbers user hooks); settings.json merge idempotent, backups hard-fail, final rewrite atomic via tempfile + rename. 🧪 9 v0.4.12 targeted regression tests for sandbox.strictMode (3) + parse strictMode + provider_match pricing + has_word o-series + stream_options 400 + meaningful-content classification + premature-EOF retry truth table (codex round-1 #3 —should_retry_on_premature_eof()extracted to pure fn, 7-row test). Bundle: 76 skills, 54 helpers (+2 meta_opt scripts vs v0.4.12). Codex 3 rounds (NO-GO + 3 → NO-GO + metadata → GO).v0.4.12 (2026-05-22) — Bug-fix + small-feature release. #238
sandbox.strictModeopt-in config key; when set,SandboxConfig::resolve_request()ignores all five LLM-supplied overrides (dangerouslyDisableSandbox,namespaceRestrictions,isolateNetwork,filesystemMode,allowedMounts) — closes the gap where a tool call could silently bypass user sandbox policy.aris doctoradds a "Sandbox:" row; bash tool schema documents the strictMode semantics. #232auto-review-loop-llmupdated from legacydeepseek-chat/deepseek-reasoner(deprecate 2026-07-24; reasoner rejectstool_choice) todeepseek-v4-flash/deepseek-v4-pro. v0.4.10 audit P1 follow-ups: P1.A Anthropic stream retry gates onhas_emitted_meaningful_content(a stream that only sentMessageStartbefore EOF is retry-eligible); P1.Bsupports_reasoning_effort+ reviewer mirror use word-boundary match soopenai/o3-mini/proxy:o4route correctly; P1.Cstream_options.include_usage:trueproxy fallback retries once without on real 400 unknown-field errors; P2 pricing match precision viaprovider_match()soqwen3.6-plus/kimi-k2.5route correctly whilemy-kimi-clonedoes not. Skills sync (76 skills, 52 helpers):/interview-cheatsheet+/render-htmlnewly bundled;build.rsALLOWED_EXTSgainshtmlfor render-html templates;EXCLUDED_SKILL_PREFIXES→starts_with("skills-codex"). CI fetch-depth: 0 + origin/main fetch so drift-test ancestor check runs. Cross-reviewed by Codex MCP (gpt-5.5 xhigh) over 4 rounds.v0.4.11 (2026-05-18) — Skills bundle refresh + sync infrastructure. The embedded skills set in the v0.4.10 binary had fallen behind main (~6 of 56 main
skills/commits had been cherry-picked); v0.4.11 syncs the full set and ships sync infrastructure so the gap can't silently reopen. Bundle: 65→74 user-facing skills, 34→49 helper resources. 10 new skills bundled:/citation-audit(fourth-layer bibliography audit),/experiment-queue(SSH multi-seed job queue with OOM retry),/kill-argument(two-thread adversarial review for theory papers),/resubmit-pipeline(W5: text-only port to a new venue),/paper-talk(end-to-end conference talk pipeline),/slides-polish(per-page Codex layout review),/overleaf-sync(two-way Overleaf Git-bridge),/gemini-search+/openalex(broader literature sources),/qzcli(Qizhi GPU jobs). 46 existing SKILL.md refreshed — most critically the canonical resolver chain rollout (closes real user incident where/research-wikiwas empty for a week from hardcodedtools/research_wiki.py), submission assurance gate + external verifier (/paper-writingPhase 6 now functions). tools/ goes 9→18: 9 baseline helpers refreshed (research_wiki.py315→767 lines with canonicalingest_paperAPI), 9 new helpers (extract_paper_style.py,figure_renderer.py,paper_illustration_image2.py,overleaf_{setup,audit}.sh,verify_wiki_coverage.sh,watchdog.py,experiment_queue/{build_manifest,queue_manager}.py). Newtools/sync_main_skills.shautomates main → bundle rsync with symlink pre-flight + codex-mirror prune +SKILLS_SOURCE_COMMITpinning. 3 new CI drift tests incrates/runtime/src/cache.rscover all 4 resolver layer patterns. Gemini MCP calls in/research-litand/gemini-searchnow passmodel: 'auto-gemini-3'(avoids silent downgrade to 2.5-pro on OAuth-personal capacity exhaustion). CLI runtime unchanged — codex-audit P1 follow-ups remain on v0.4.12 backlog. Cross-reviewed by Codex MCP (gpt-5.5 xhigh) across 5 rounds (REQUEST CHANGES → APPROVE WITH NITS → NO-GO → GO → final GO).v0.4.10 (2026-05-17) — Stream + MCP reliability + multi-provider pricing. C6 whole-stream restart in Anthropic
MessageStream+ OpenAI SSE loop on chunk decode failure / premature EOF (ARIS_STREAM_RETRY, default 2, clamp 0..=5, fires only when nothing emitted yet — closes #228-style "error decoding response body" loop). M3 MCP stdio gains 300s defaulttokio::time::timeoutover send+read (overrideMCP_REQUEST_TIMEOUT_SECS, clamp 1..=1800);response.id ↔ request.idcorrelation;ensure_server_ready()try_wait()dead-process respawn;kill().awaiton all failure paths so the next call starts clean (closes #151 / #172 "Calling codex..." stalls). C8/P4 OpenAI streaming requests now sendstream_options.include_usage:true+ parsecached_tokens; Anthropic streaming mergesMessageStart.usage(input/cache) withMessageDelta.usage(output). C9 multi-provider pricing registry (15+ models, OpenAI cache_read = input × 0.1 corrects 5× generic overstatement, DeepSeek cache_hit/cache_miss tiers,has_word()boundary matcher forprovider/<model>slugs). 9 dead-code warnings cleared;aris setuphelp text synced with actual behaviour.v0.4.9 (2026-05-17) — Closes Codex v0.4.7 audit residuals (L1 TLS double-stack, L3 reasoning_cache compaction misalign, L4 reasoning replay unbounded). 2 new skills bundled (
/figure-spec+/paper-illustration-image2withscripts/subdirs, new Layer 0b =$ARIS_CACHE_DIR/skills/<name>/scripts/);research_wiki.pypromoted to sharedtools/(9+ callers); 5 more SKILL.md migrated to fallback chain.v0.4.8 (2026-05-17) — Skill helper subsystem rewrite. Bundled helpers extract to
~/.config/aris/cache/<version>/at startup; every Skill invocation surfaceshelperReportJSON + 4-layer resolver preamble;/skills exportcopies helpers; newintegration-contract.mdwith 6 failure policies; 8 shared helpers (arxiv/deepxiv/exa/S2/openalex/save_trace/verify_papers/verify_paper_audits) bundled;/research-lit+/deepxivmigrated. Plus 4 bug fixes: gpt-5.5+tools 400 on OpenAI; Custom reviewer reset; missingsignaturefield (#228);--versionBuild date hardcoded.v0.4.7 (2026-05-16) — DashScope Coding Plan 405 fixed (#159) via
native-tlsswitch (#225);reasoning_contentreplay for all reasoning models (OpenAI o1/o3/o4 / DeepSeek-R1 etc.), not just Kimi (#226); 600+ lines dead code cleanup +rustylinedep removed + "Claw Code" → "ARIS-Code" rebrand.v0.4.6 (2026-05-14) — 🚨 Two long-standing silent bugs fixed:
PermissionMode::Promptsilently allowed every tool (derived-Ordbug); system prompt hardcodedcurrent_date = "2026-03-31"made models reject post-cutoff data as future/prompt-injection. Plus Custom OpenAI-compatible provider (/setupoption 11) with dynamic/modelsdiscovery (@Anduin9527 #221 + #222).v0.4.5 (2026-05-13) — First-class reasoning-model support: thinking content blocks end-to-end (fixes #161) +
reasoning_effort='xhigh'for GPT-5.5 / o1 / o3 / o4 / DeepSeek-thinking. DeepSeek V4 Pro + Xiaomi MiMo + Qwen 3.6 + Doubao in/setup(options 7-10). Object-style hooks parser. Default model bumped to Claude Opus 4.7 + GPT-5.5. REPL input hardening (multi-line wrap / Cmd+V paste / CJK boundary). GitHub Actions CI. Credits: @GO-player-hhy (#186), @Jxy-yxJ (#171), @GetIT-Sunday (#216 partial).Older versions
v0.4.4 (2026-04-20) — Setup UX + reviewer routing fixes (resolves #158, #162) |
/setupno longer forces Bearer for Anthropic + custom URL | Provider-aware proxy URL hints | Stale state no longer leaks across provider switches | LlmReview smart fallbackv0.4.3 (2026-04-17) — Third-party Anthropic-compat proxy support (Bedrock etc.) | Skip beta flags that proxies reject | Propagate custom base URL for
anthropicprovider | Credit @screw-44v0.4.2 (2026-04-17) — Auto-compaction corruption fix | Compaction summary preserved on OpenAI-compat executors | Shell-provided API keys no longer erased on launch
v0.4.1 (2026-04-15) — Plan mode (
/plan) | Cooperative Ctrl+C interrupt | Auto-retry (429/5xx/network) | Research Wiki 📚 (persistent knowledge base) | Self-Evolution 🧬 (/meta-optimize) | Local models (LM Studio/Ollama) | 62 skills syncedv0.3.11 (2026-04-13) — Reviewer Anthropic-compatible mode (Claude via proxy)
v0.3.9 (2026-04-11) — Proxy/custom base URL (CCSwitch) | Local models (LM Studio/Ollama) | Windows (experimental)
v0.3.5 (2026-04-08) — Research Wiki (persistent papers/ideas/experiments/claims + relationship graph) | Meta-Optimize self-evolution (analyze logs → propose SKILL.md patches)
v0.3.0 (2026-04-03) — Multi-file memory index | Rich task system (TodoWrite) |
/plan| Security hardeningv0.2.2 (2026-04-03) —
/planstep-by-step planning |/taskspersistent trackingv0.2.1 (2026-04-03) — Persistent Memory | Kimi K2.5 multi-turn fix | CJK cursor fix
v0.2.0 (2026-04-02) — Open source | Kimi + MiniMax + GLM support | Smart LlmReview routing | CI/CD
v0.1.0 (2026-04-02) — Initial release | Multi-executor & reviewer | 42 bundled skills
中文版 README | English
🌙 Let Claude Code do research while you sleep. Wake up to find your paper scored, weaknesses identified, experiments run, and narrative rewritten — autonomously.
🪶 Radically lightweight — zero dependencies, zero lock-in. The entire system is plain Markdown files. No framework to learn, no database to maintain, no Docker to configure, no daemon to babysit. Every skill is a single
SKILL.mdreadable by any LLM — swap Claude Code for Codex CLI, OpenClaw, Cursor, Trae, Antigravity, Copilot CLI, Windsurf, or your own agent and the workflows still work. Fork it, rewrite it, adapt it to your stack.💡 ARIS is a methodology, not a platform. What matters is the research workflow — take it wherever you go. 🌱
Custom Claude Code skills for autonomous ML research workflows. These skills orchestrate cross-model collaboration — Claude Code drives the research while an external LLM (via Codex MCP) acts as a critical reviewer. 🔀 Also supports alternative model combinations (Kimi, LongCat, DeepSeek, etc.) — no Claude or OpenAI API required. For example, MiniMax-M2.7 + GLM-5 or GLM-5 + MiniMax-M2.7. 🤖 Codex CLI native — full skill set also available for OpenAI Codex. 🖱️ Cursor — works in Cursor too. 🖥️ Trae — ByteDance AI IDE. 🚀 Antigravity — Google's agent-first IDE. 🐙 Copilot CLI — GitHub's terminal agent (native SKILL.md + MCP). 🆓 Free tier via ModelScope — zero cost, zero lock-in.
💭 Why not self-play with a single model? Using Claude Code subagents or agent teams for both execution and review is technically possible, but tends to fall into local minima — the same model reviewing its own patterns creates blind spots.
Think of it like adversarial vs. stochastic bandits: a single model self-reviewing is the stochastic case (predictable reward noise), while cross-model review is adversarial (the reviewer actively probes weaknesses the executor didn't anticipate) — and adversarial bandits are fundamentally harder to game.
💭 Why two models, not more? Two is the minimum needed to break self-play blind spots, and 2-player games converge to Nash equilibrium far more efficiently than n-player ones. Adding more reviewers increases API cost and coordination overhead with diminishing returns — the biggest gain is going from 1→2, not 2→4.
Claude Code's strength is fast, fluid execution; Codex (GPT-5.4 xhigh) is slower but more deliberate and rigorous in critique. These complementary styles — speed × rigor — produce better outcomes than either model talking to itself.
🧿 Want the strongest possible reviewer? Add
— reviewer: oracle-proto any skill to route reviews through GPT-5.4 Pro via Oracle MCP. Pro-level reasoning for proof verification, experiment auditing, and final stress tests. Works with API key or free browser mode. Setup →
Contents
- More Than Just a Prompt
- What's New · changelog
- Quick Start · install + first run
- Features
- Score Progression (Real Run)
- Community Showcase — Papers Built with ARIS
- Awesome Community Skills & Extensions
- Workflows · 13 named pipelines (W1 / W1.5 / W2 / W3 / W4 / W5 / W6 / Wiki / WM + Effort / Assurance / Oracle)
- Skills Catalog
- Setup · prerequisites / install / update / usage / GPU server config
- Customization · per-skill config knobs
- Alternative Model Combinations · GLM / MiniMax / Kimi / etc.
- Community
- Citation
- Star History
- Acknowledgements
- License
1. 🎯 More Than Just a Prompt
These are full pipelines — you can also use each workflow independently. Already have an idea? Skip to Workflow 1.5. Have results? Jump to Workflow 3. Got reviews? Jump to Workflow 4. Want persistent memory? Enable Research Wiki. See Quick Start for all commands and Workflows for the full breakdown.
Basic mode — give ARIS a research direction, it handles everything:
/research-pipeline "factorized gap in discrete diffusion LMs"
🔥 Targeted mode — got a paper you want to improve? Give ARIS the paper + the code:
/research-pipeline "improve method X" — ref paper: https://arxiv.org/abs/2406.04329, base repo: https://github.com/org/project
ARIS reads the paper → finds its weaknesses → clones the codebase → generates ideas that specifically fix those weaknesses with that code → runs experiments → writes your paper. Like telling a research assistant: "read this paper, use this repo, find what's missing, and fix it."
Mix and match:
ref paperonly = "what can be improved?",base repoonly = "what can I build with this code?", both = "improve this paper using this code."
🔥 Rebuttal mode — reviews just dropped? Don't panic. ARIS reads every concern, builds a strategy, and drafts a rebuttal that's grounded, structured, and under the character limit:
/rebuttal "paper/ + reviews" — venue: ICML, character limit: 5000
Three safety gates — rebuttal will NOT finalize if any fails:
- 🔒 No fabrication — every claim maps to paper/review/user-confirmed result
- 🔒 No overpromise — every promise is user-approved
- 🔒 Full coverage — every reviewer concern is tracked
Two outputs: PASTE_READY.txt (exact char count, paste to venue) + REBUTTAL_DRAFT_rich.md (extended version for manual editing).
Show rebuttal parameters — venue, character limit (required), quick mode, auto experiment, stress test rounds, followup rounds
| Parameter | Default | What it does |
|---|---|---|
venue | ICML | Target venue (ICML/NeurIPS/ICLR/CVPR/ACL/AAAI/ACM) |
character limit | — | Required. Hard character limit for rebuttal text |
quick mode | false | Stop after parsing + strategy (Phase 0-3). See what reviewers want before drafting |
auto experiment | false | Auto-run supplementary experiments via /experiment-bridge when reviewers ask for new evidence |
max stress test rounds | 1 | How many times GPT-5.4 xhigh stress-tests the draft |
max followup rounds | 3 | Per-reviewer follow-up round limit |
After acceptance — your paper is in, now prepare the presentation:
/paper-slides "paper/" # → Beamer PDF + PPTX + speaker notes + Q&A prep
/paper-poster "paper/" # → A0/A1 poster PDF + editable PPTX + SVG
💡 From idea to paper to podium — one toolchain. 🌱